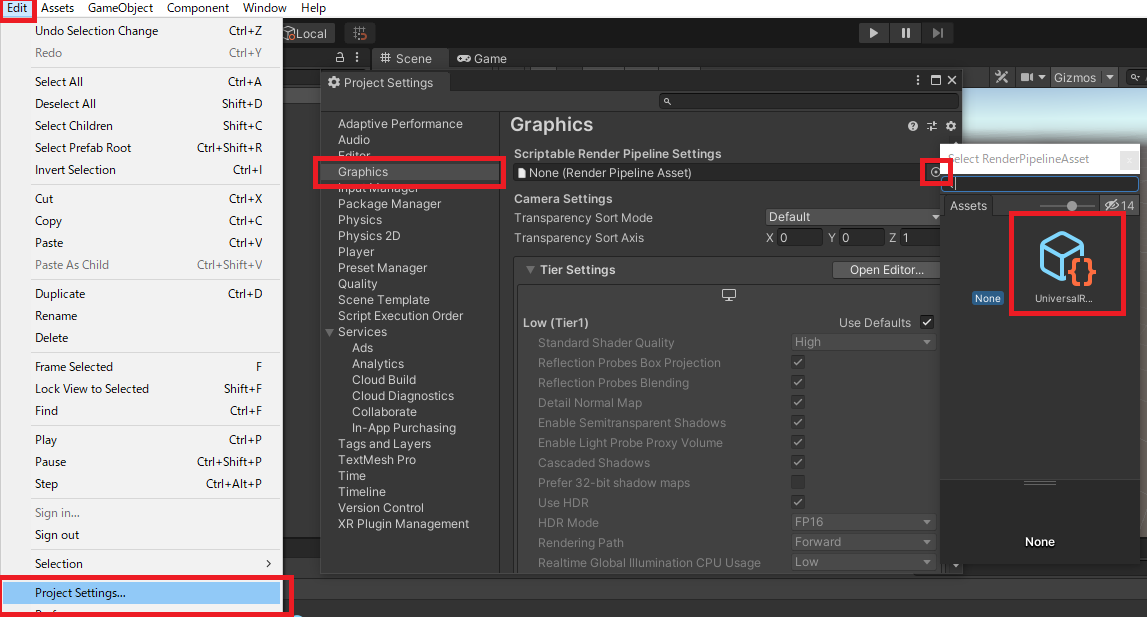
数式扱うようなビジュアル プログラミングなんて死んでもやりたくありません。馬鹿じゃねぇの?
というわけで、なんとか自分でURPのシェーダを書いてみます。
自動生成された Lit シェーダを読んでみた
生成されたコードを見るみたいなボタンがあったので押してみると、2000行にも及ぶシェーダーコード。辛そう………。
泣く泣く読んでみると、沢山の Pass がありました。取りあえずLiteModeでgrepかけると、以下のパスがありました。殆どのパスはtargetが4.5と2.0で2つ作られるようです。
| Pass |
説明 |
target |
| UniversalForward |
最終的に画面に出すレンダリングパスかな。 |
4.5 / 2.0 |
| UniversalGBuffer |
光の計算はせずにジオメトリを出力するパス。defferdレンダリング用。 |
4.5 |
| ShadowCaster |
シャドウマップかデプステクスチャにレンダリングするパス。 |
4.5 / 2.0 |
| DepthOnly |
デプステクスチャに書き込むパス。 |
4.5 / 2.0 |
| DepthNormals |
URPバージョン10.0.xからの _CameraNormalsTexture を作成するときに使うパス。 |
4.5 / 2.0 |
| Meta |
Unity エディターでライトマップをベイク処理するときに使うパス。 |
4.5 / 2.0 |
| Universal2D |
2Dレンダラで使うパス。 |
4.5 / 2.0 |
| SceneSelectionPass |
Sceneビューで選択されたオブジェクトの境界を標示するためのパス |
4.5/2.0 |
| Picking |
Sceneビューで選択する領域を定義するためのパス |
4.5/ 2.0 |
また、コードの殆どは型変換のコードばかりで、実質的には100行もないのではないでしょうか。
型変換コードが大量にあるのは、たぶん、Shader Graphの表現型をそのままコードに落とし込むためかなぁ。無駄な情報の最適化とかはコンパイラで頑張るのでしょうね。
うん、何となく分かったから、手書きできそうかな?
UnityとしてはShaderGraphがコア機能になってるので、ShaderLabではなく、ShaderGraphを推奨してるのでしょうが、面倒なのでやりたくない。
ただ、DepthNormalsみたく、URPはまだまだ変更が多く加わるので、バージョンという面ではShaderGraphによる自動生成が良いのでしょう。
とりあえずの結論としては、一度手書きでコードを作成した後に ShaderGraph を作れるなら作るというのが良い気がします。(発想が逆ぅ!)
とりあえず、テクスチャだけ表示するシェーダを作る
さっくりできた。
hogeシェーダー
Shader "Unlit/hoge"
{
Properties
{
[MainTexture] _BaseMap ("Texture", 2D) = "white" {}
}
SubShader
{
Tags
{
"RenderPipeline"="UniversalPipeline"
"RenderType"="Opaque"
}
Pass
{
Name "Universal Forward"
Tags
{
"LightMode" = "UniversalForward"
}
Cull Back
ZTest LEqual
ZWrite On
HLSLPROGRAM
#pragma target 4.5
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 pos: POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
float2 uv : TEXCOORD1;
UNITY_VERTEX_INPUT_INSTANCE_ID
UNITY_VERTEX_OUTPUT_STEREO
};
sampler2D _BaseMap;
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
CBUFFER_END
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
UNITY_TRANSFER_INSTANCE_ID(i, o);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
o.uv = TRANSFORM_TEX(i.uv, _BaseMap);
return o;
}
half4 frag (v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
half4 baseColor = tex2D(_BaseMap, i.uv);
return baseColor;
}
ENDHLSL
}
}
}
URPでは空間の変換は取りあえず GetVertexPositionInputs にぶん投げておけばワールド空間、クリップ空間、ビュー空間の座標に一気に変換してくれるっぽい。
コメントを信じるなら、要らない変数はコンパイラが頑張って削除してくれるので気にしなくて良いよとのこと。
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
UNITY_TRANSFER_INSTANCE_ID(i, o);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
o.uv = TRANSFORM_TEX(i.uv, _BaseMap);
return o;
}

影を表示する
シャドウマップから情報持ってきて、影を表示してみたいとおもいます。実装したのが以下。
mogeシェーダ
Shader "Unlit/moge"
{
Properties
{
[MainTexture] _BaseMap ("Texture", 2D) = "white" {}
}
SubShader
{
Tags
{
"RenderPipeline"="UniversalPipeline"
"RenderType"="Opaque"
}
Pass
{
Name "Universal Forward"
Tags
{
"LightMode" = "UniversalForward"
}
Cull Back
ZTest LEqual
ZWrite On
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ _MAIN_LIGHT_SHADOWS
#define _MAIN_LIGHT_SHADOWS_CASCADE
#define _SHADOWS_SOFT
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
struct appdata
{
float4 pos: POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
float2 uv : TEXCOORD1;
float4 shadowCoord : TECOORD4;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
sampler2D _BaseMap;
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
CBUFFER_END
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
UNITY_TRANSFER_INSTANCE_ID(i, o);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
o.uv = TRANSFORM_TEX(i.uv, _BaseMap);
o.shadowCoord = GetShadowCoord(vInput);
return o;
}
half4 frag (v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
half4 baseColor = tex2D(_BaseMap, i.uv);
Light light = GetMainLight(i.shadowCoord);
half shadow = light.shadowAttenuation * light.distanceAttenuation;
return baseColor * half4(shadow, shadow, shadow, 1);
}
ENDHLSL
}
}
}
とりあえず、影に関するキーワードは以下ぐらいあるみたいです。
#pragma multi_compile _ _MAIN_LIGHT_SHADOWS
#define _MAIN_LIGHT_SHADOWS_CASCADE
#define _SHADOWS_SOFT
_MAIN_LIGHT_SHADOWS のキーワードを定義するとメインライトに対する影の処理が有効になります。以下の参考記事によると、これは固定でdefineしたらダメっぽい。
_MAIN_LIGHT_SHADOWS_CASCADE と _SHADOWS_SOFT はデフォルトONでいいよね?よくわからんけどって感じでdefineで定義してみました。
参考
で、Lightingの為のhlslをインクルード
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
v2f にシャドウマップから取得するための情報を格納。
struct v2f
{
float4 shadowCoord : TECOORD4;
};
o.shadowCoord = GetShadowCoord(vInput);
フラグメントシェーダで取りあえず、影の分だけ暗くするようにしました。
Light light = GetMainLight(i.shadowCoord);
half shadow = light.shadowAttenuation * light.distanceAttenuation;
return baseColor * half4(shadow, shadow, shadow, 1);
で、結果が以下………あれ?なんもかわらんね?

うーん、もしかして ShadowCaster のパスを実装しないとダメなのかな?というわけで、以下の一文を追加。
UsePass "Universal Render Pipeline/Lit/ShadowCaster"

おぉ、影がついた。
ShadowCaster のパスは必須みたいですね。
ShadowCasterも自分で実装してみる
ShadowCasterも自力で実装してみます。
moge2シェーダ
Shader "Unlit/moge2"
{
Properties
{
[MainTexture] _BaseMap ("Texture", 2D) = "white" {}
}
SubShader
{
Tags
{
"RenderPipeline"="UniversalPipeline"
"RenderType"="Opaque"
}
Pass
{
Name "Universal Forward"
Tags
{
"LightMode" = "UniversalForward"
}
Cull Back
ZTest LEqual
ZWrite On
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ _MAIN_LIGHT_SHADOWS
#define _MAIN_LIGHT_SHADOWS_CASCADE
#define _SHADOWS_SOFT
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
struct appdata
{
float4 pos: POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
float2 uv : TEXCOORD1;
float4 shadowCoord : TECOORD4;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
sampler2D _BaseMap;
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
CBUFFER_END
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
UNITY_TRANSFER_INSTANCE_ID(i, o);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
o.uv = TRANSFORM_TEX(i.uv, _BaseMap);
o.shadowCoord = GetShadowCoord(vInput);
return o;
}
half4 frag (v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
half4 baseColor = tex2D(_BaseMap, i.uv);
Light light = GetMainLight(i.shadowCoord);
half shadow = light.shadowAttenuation * light.distanceAttenuation;
return baseColor * half4(shadow, shadow, shadow, 1);
}
ENDHLSL
}
Pass
{
Name "ShadowCaster"
Tags
{
"LightMode" = "ShadowCaster"
}
Cull Back
ZTest LEqual
ZWrite On
ColorMask 0
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 pos: POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
};
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
return o;
}
half4 frag (v2f i) : SV_Target
{
return 0;
}
ENDHLSL
}
}
}
ShadowCasterはめっちゃ単純に入力された頂点をクリップ空間に変換し、色は0を出力してるだけです。
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
return o;
}
half4 frag (v2f i) : SV_Target
{
return 0;
}
これで表示すると………

あれー?まだテクスチャ貼ってない段階だけど、何か酷いことになった………。何この縞模様。
で、正常に表示されている Lit シェーダのShadowCasterを覗いてみると、vertexシェーダのクリップ空間の計算が、以下の様になっていました。
float3 positionWS = TransformObjectToWorld(input.positionOS.xyz);
float3 normalWS = TransformObjectToWorldNormal(input.normalOS);
float4 positionCS = TransformWorldToHClip(ApplyShadowBias(positionWS, normalWS, _LightDirection));
#if UNITY_REVERSED_Z
positionCS.z = min(positionCS.z, positionCS.w * UNITY_NEAR_CLIP_VALUE);
#else
positionCS.z = max(positionCS.z, positionCS.w * UNITY_NEAR_CLIP_VALUE);
#endif
return positionCS;
ApplyShadowBias というのが重要っぽいケド、なんだろこれ。というわけで、 Shader.hlsl を覗いてみます。
float3 ApplyShadowBias(float3 positionWS, float3 normalWS, float3 lightDirection)
{
float invNdotL = 1.0 - saturate(dot(lightDirection, normalWS));
float scale = invNdotL * _ShadowBias.y;
positionWS = lightDirection * _ShadowBias.xxx + positionWS;
positionWS = normalWS * scale.xxx + positionWS;
return positionWS;
}
うーんと、要するに、ライト方向に移動させて、法線方向に拡大or縮小してるのかな。
あー。そっか、おっさんようやく意味が分かった。
あの縞模様って「自分自身の影」を表示しちゃってるんだ。だから、「若干ライトから見て奥に移動」と「若干縮小」で表面が自分の影に入らない様にしてるんだね。
というわけで、以下のインクルードと、定数を追加。 なお、CommonMaterial.hlsl をインクルードしないと Shadows.hlsl で関数定義不足でエラーになった。(これ、バグじゃない?)
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/CommonMaterial.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Shadows.hlsl"
float3 _LightDirection;
で、頂点シェーダを以下の様に書き換え。
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
float3 normalWS = TransformObjectToWorldNormal(i.normal);
o.pos = TransformWorldToHClip(ApplyShadowBias(vInput.positionWS, normalWS, _LightDirection));
#if UNITY_REVERSED_Z
o.pos.z = min(o.pos.z, o.pos.w * UNITY_NEAR_CLIP_VALUE);
#else
o.pos.z = max(o.pos.z, o.pos.w * UNITY_NEAR_CLIP_VALUE);
#endif
return o;
}
UNITY_REVERSED_Z は OpenGL系とDirectXでデプスが0~1か、1~0かで違うのを吸収する為っぽい。中の数式(min、max)は良く意味が分からんけど、何かの飽和処理なんでしょう。ライトの画面外にでた場合でも表示するためかな。

上手く影でました。
moge3シェーダー
Shader "Unlit/moge3"
{
Properties
{
[MainTexture] _BaseMap ("Texture", 2D) = "white" {}
}
SubShader
{
Tags
{
"RenderPipeline"="UniversalPipeline"
"RenderType"="Opaque"
}
Pass
{
Name "Universal Forward"
Tags
{
"LightMode" = "UniversalForward"
}
Cull Back
ZTest LEqual
ZWrite On
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#pragma multi_compile _ _MAIN_LIGHT_SHADOWS
#define _MAIN_LIGHT_SHADOWS_CASCADE
#define _SHADOWS_SOFT
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
struct appdata
{
float4 pos: POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
float2 uv : TEXCOORD1;
float4 shadowCoord : TECOORD4;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
sampler2D _BaseMap;
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
CBUFFER_END
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
UNITY_TRANSFER_INSTANCE_ID(i, o);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
o.pos = vInput.positionCS;
o.uv = TRANSFORM_TEX(i.uv, _BaseMap);
o.shadowCoord = GetShadowCoord(vInput);
return o;
}
half4 frag (v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
half4 baseColor = tex2D(_BaseMap, i.uv);
Light light = GetMainLight(i.shadowCoord);
half shadow = light.shadowAttenuation * light.distanceAttenuation;
return baseColor * half4(shadow, shadow, shadow, 1);
}
ENDHLSL
}
Pass
{
Name "ShadowCaster"
Tags
{
"LightMode" = "ShadowCaster"
}
Cull Back
ZTest LEqual
ZWrite On
ColorMask 0
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/CommonMaterial.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Shadows.hlsl"
struct appdata
{
float4 pos: POSITION;
float3 normal: NORMAL;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
};
float3 _LightDirection;
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz);
float3 normalWS = TransformObjectToWorldNormal(i.normal);
o.pos = TransformWorldToHClip(ApplyShadowBias(vInput.positionWS, normalWS, _LightDirection));
#if UNITY_REVERSED_Z
o.pos.z = min(o.pos.z, o.pos.w * UNITY_NEAR_CLIP_VALUE);
#else
o.pos.z = max(o.pos.z, o.pos.w * UNITY_NEAR_CLIP_VALUE);
#endif
return o;
}
half4 frag (v2f i) : SV_Target
{
return 0;
}
ENDHLSL
}
}
}
輪郭を表示
URPでも昔ながらの前面カリングで輪郭線を付けれるみたいなので、やってみます。
まずは、 「Edit」→「Project Settings...」を開いて、「Tags and Layers」を表示して、適当な Outlined レイヤーを追加

そうしたら、輪郭を表示したいオブジェクトのLayerをOutlinedに変更。

で、こんな感じのテキトーなアウトライン表示用のシェーダとマテリアルを用意。
outlineシェーダ
Shader "Unlit/outline"
{
Properties
{
_BaseMap ("Texture", 2D) = "black" {}
_Width ("Width", float) = 0.01
}
SubShader
{
Tags
{
"RenderPipeline"="UniversalPipeline"
"RenderType"="Opaque"
"UniversalMaterialType" = "Lit"
"Queue"="Geometry"
}
Pass
{
Name "Universal Forward"
Tags
{
"LightMode" = "UniversalForward"
}
Cull Front
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#pragma multi_compile _ DOTS_INSTANCING_ON
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
struct appdata
{
float4 pos: POSITION;
float3 normal: NORMAL;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 pos : SV_POSITION;
float2 uv : TEXCOORD0;
};
sampler2D _BaseMap;
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
float _Width;
CBUFFER_END
v2f vert (appdata i)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(i);
VertexPositionInputs vInput = GetVertexPositionInputs(i.pos.xyz + i.normal * _Width);
o.pos = vInput.positionCS ;
o.uv = TRANSFORM_TEX(i.uv, _BaseMap);
return o;
}
half4 frag (v2f i) : SV_Target
{
return tex2D(_BaseMap, i.uv);
}
ENDHLSL
}
}
}
URP の Renderer Data のInspectorを開いて、「Add Rendrer Feature」からRender Objects を追加し、こんな感じで設定。

OverridesのMaterialでoutlineを指定してシェーダーを変更するというやり方らしい。
こんな感じで球体に輪郭線が出ました。

Unityのシェーダーが微粒子レベルぐらいはわかってきたかなぁ。いや、もう調べれば調べるほど色々出てきて収拾つかないね。