一度CMake化してしまうと、GUI が面倒臭いのであれもこれも Make コマンドから実行したくなります。
というわけで、さらにCMakeを強化したのでメモ
目次
追加
- report_addr_${project} : 設定したアドレスの一覧を出力する。GUI を見ないと確認できないのが馬鹿じゃないのかと常々思ってた。
- open_project: Vivado のプロジェクトをGUIで開く。Explorer でダブルクリックするのが面倒臭いし、パスを指定するのも面倒臭かった。
- program_project: BitStream を書き込む。xsdb で connect→target →fpga とかやるのが面倒臭かった。
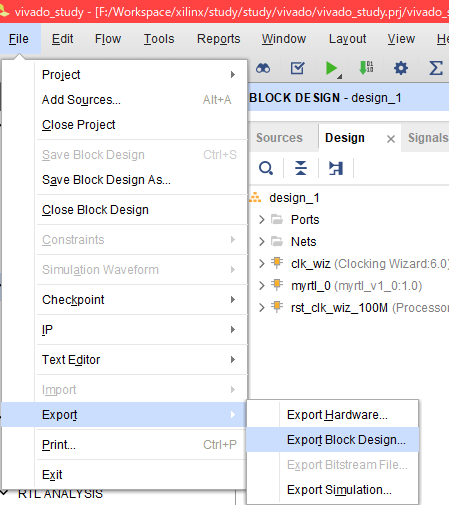
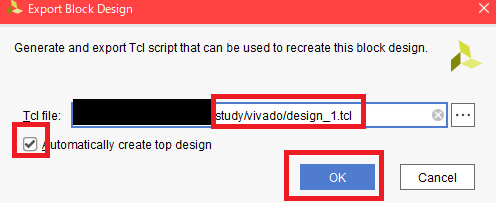
- export_bd_project: DesignのTCLファイルを出力する。Fileメニューからパスを指定して保存するのが面倒臭かった。
- Vivado_HLSでも動作するように修正
FindXXXの検索パスの追加
以下の様にして追加。
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} ${CMAKE_CURRENT_SOURCE_DIR}/cmake)
Vivado
find_package(Vivado REQUIRED) で読み込む。
XILINX_VIVADO か、 VIVADO_ROOT 変数からvivadoのパスを検索する。
CMakeのVIVADO_VERSION が定義されるので、読み込んだVivadoのバージョンが幾つか確認できる。
Vivadoプロジェクト定義
add_vivado_project( <project> BOARD <board name> TOP <top module> [DIR <directory name>] [RTL <file/directory>...] [CONSTRAINT <file/directory>...] [IP <directory>...] [DESIGN <tcl file>] [DEPENDS <target>...] )
引数
<project>: プロジェクト名BOARD <name>: ボードパートの名前TOP <name>: トップモジュールの名前
オプション引数
DIR <dir>: プロジェクトのディレクトリ名。(デフォルトは<projet>.prj)RTL <path>...: RTL ファイル・ディレクトリ。複数のパスを指定可能CONSTRAINT <path>...: 制約ファイル・ディレクトリ。複数のパスを指定可能IP <path>...: IPディレクトリ(HLSで合成した物含む)。複数のパスを指定可能DESIGN <TCL file>: ボードデザインのTCLファイルDEPENDS <target>...: 依存ターゲット。複数指定可能
定義されるターゲット
| ターゲット名 | 説明 |
|---|---|
<project> |
Vivadoプロジェクトの作成 |
open_<project> |
作成したVivadoプロジェクトをGUIで開く |
clear_<project> |
プロジェクトディレクトリを削除 |
impl_<project> |
ビットストリームを作成する。 ビルドディレクトリ直下のbitディレクトリにコピーされる |
program_<project> |
ビットストリームを書き込む.詳細後述 |
export_bd_<project> |
デザインのボードファイルをDESIGNで指定したファイルに出力。 |
report_addr_<project> |
アドレスの情報を出力.詳細後述 |
program_<project>
make JTAG=ターゲット番号 [XSDB_URL=URL] program_<project>
JTAG: JTAGの番号。未指定の場合は、ターゲット一覧を表示して終了するXSDB_URL: ローカルサーバー以外のhw_serverを指定する
report_addr_<project>
make [REPORT_CSV=file] report_addr_<project>
REPORT_CSV: 出力するCSVファイル名
現状は以下の様な内容を出力
Offset, Range, Access, Usage, Path, NAME 0x00000000,0x00010000,read-write,register,/JTAG/Data/SEG_axi_gpio_0_Reg,SEG_axi_gpio_0_Reg 0x00020000,0x00010000,read-write,register,/JTAG/Data/SEG_hlsled_0_Reg,SEG_hlsled_0_Reg
HLS
find_package(HLS REQUIRED) で読み込む。
VitisはXILINX_HLS か、 VITIS_ROOT 変数から vitis_hls のパスを検索する。
VivadoはXILINX_VIVADO か、 VIVADO_ROOT 変数からvivado_hlsのパスを検索する。
VivadoとVitisではVitisが優先される。
CMakeのHLS_VERSION が定義されるので、読み込んだVitis/Vivado HLSのバージョンが幾つか確認できる。
Vitis/Vivadoの確認は HLS_IS_VIVADOと HLS_IS_VITIS 変数が TRUEかFALSEかで判断できる。
HLS プロジェクトの定義
add_hls_project( <project> TOP <top module> PERIOD <clock period(ns)> PART <board part> SOURCES <C++ source file>... [INCDIRS <include directory>...] [LINK <link library>...] [TB_SOURCES <test bench C++ file>...] [TB_INCDIRS <include directory>...] [TB_LINK <link libray>...] [DEPENDS <depends target>...] [NAME <display name>] [IPNAME <IP name>] [VENDOR <your name>] [TAXONOMY <category>] [VERSION <version(x.y)>] [SOLUTION <solution name>] [COSIM_LDFLAGS <flag string>] [COSIM_TRACE_LEVEL <none|all|port|port_hier>] )
add_hls_project(
定義されるターゲット
| ターゲット名 | 説明 |
|---|---|
create_project_<project> |
HLS プロジェクトを作成する |
open_<project> |
HLS プロジェクトをGUIで開く |
clear_<projec> |
HLS プロジェクトを削除する |
csynth_<project> |
高位合成をする |
cosim_<project> |
C/RTL シミュレーションを実行する |
lib_<project> |
C++のコンパイル |
test_<project> |
テストベンチのコンパイル |
引数
project: プロジェクト名TOP <name>: トップモジュール名PERIOD <ns>: クロック周期(ナノ秒)PART <name>: デバイスの part名SOURCES <C++ source file>...: HLSのC++ソースファイル(ヘッダは不要)
オプション引数
NAME <name>: IP の表示される名前.スペースを使っていいIPNAME <name>: IP名。スペースは使っちゃダメVENDOR <name>: 作成者の名前TAXONOMY <name>: よくわからんけど、IPのカテゴリ名らしいVERSION <x.y>: IP version(x.y)SOLUTION <name>: ソリューション名TB_SOURCES <C++ source file>...: テストベンチのC++ソースファイル(ヘッダは不要)INCDIRS <directory>...: HLSのインクルードディレクトリTB_INCDIRS <directory>...: テストベンチの追加インクルードディレクトリDEPENDS <target>...: プロジェクト生成に必要な依存ターゲットLINK <name>...: HLSの合成に必要なリンクライブラリTB_LINK <name>...: テストベンチのコンパイルに必要な追加のリンクライブラリCOSIM_LDFLAGS <string>: cosim_designに渡す-ldflagsCOSIM_TRACE_LEVEL <none, all, port, port_hier>: よくしらん。